
The patterns of Focal Data Modeling and Identity Resolution with Patrik Lager
AgileData Podcast #82
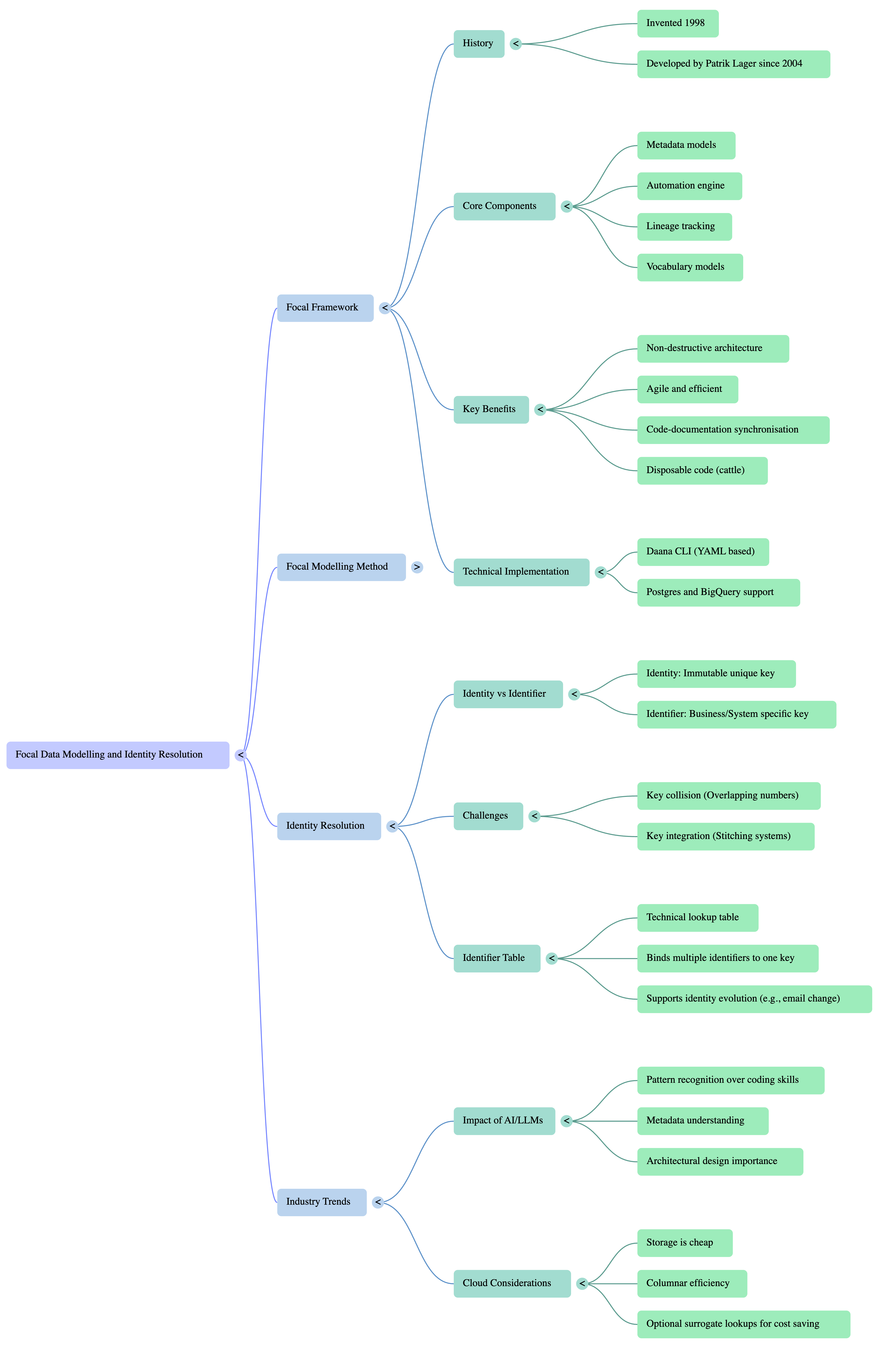
In this episode of the Agile Data Podcast, where host Shane Gibson sits down with Patrik Lager, a data integration expert with 25 years of experience and a lead developer of the Focal framework.
In this episode, the conversation explores the intricate world of Focal data modeling and identity resolution. Patrik explains how the Focal framework operates as a highly abstract, metadata-driven engine that creates an extremely agile, non-destructive architecture. By focusing on understanding the business and using documentation to generate code, Focal ensures that your architecture and documentation are always perfectly in sync.
The discussion also dives deep into the complexities of identity resolution, clarifying the crucial differences between stable “identities” (surrogate keys) and system-specific “identifiers”. Patrik breaks down how the Focal framework prevents key collisions and achieves seamless key integration across multiple source systems using a specialized identifier table.
Whether you are curious about ensemble modeling techniques, how AI and metadata-driven automation are changing data engineering, or want to learn about the new Daana command-line interface (CLI) that makes implementing Focal easier than ever, this episode is packed with valuable insights for data professionals.
Listen
Listen on all good podcast hosts or over at:
Subscribe: Apple Podcast | Spotify | Google Podcast | Amazon Audible | TuneIn | iHeartRadio | PlayerFM | Listen Notes | Podchaser | Deezer | Podcast Addict |
You can get in touch with Patrik via LinkedIn or over at https://daana.dev
Tired of vague data requests and endless requirement meetings? The Information Product Canvas helps you get clarity in 30 minutes or less?
Google NotebookLM Mindmap
Google NoteBookLM Briefing
Executive Summary
The Focal framework is a mature, metadata-driven approach to data warehousing and integration that prioritizes non-destructive architecture and business understanding over manual coding. Developed and refined since 1998, Focal employs a specific form of ensemble modeling that decomposes data into three core components: keys, descriptions, and relationships.
The framework’s primary strength lies in its “documentation-first” methodology, where a massive metadata layer (consisting of approximately 80 tables) generates the physical implementation. This ensures that documentation and code remain perfectly synchronized while making the physical layer “cattle”—disposable and easily regenerated. In the context of identity resolution, Focal provides a robust technical pattern using an “Identifier Table” to map multiple, changing business identifiers to a single, immutable identity. As the industry shifts toward AI and Large Language Models (LLMs), the framework’s highly patterned, metadata-rich structure positions it as an efficient alternative to traditional, manual coding practices.
--------------------------------------------------------------------------------
1. The Focal Framework: Philosophy and Automation
The Focal framework is distinguished from other methodologies by its tight coupling of data modeling patterns and a technical automation engine. It is designed to create a “non-destructive architecture” that allows for rapid changes without affecting existing structures.
The Documentation-First Approach
A central tenet of the Focal framework is that the value of data warehousing lies in the understanding of the business, not the code itself.
Metadata over Code: The framework captures metadata models, mappings, and rules into a repository. This metadata then generates the necessary code and holds comprehensive lineage (business, technical, and operational).
Disposable Code: In this paradigm, metadata is treated as a “pet” (highly valued and preserved), while code is treated as “cattle” (disposable and easily replaced).
Synchronization: Because the documentation (metadata) creates the code, the two are never out of sync, solving a common problem in long-term data warehouse maintenance.
Structural Complexity and Learning Curve
Despite its efficiency, Focal has historically faced a low adoption rate outside of specific European regions due to its abstract nature. It is often described as an “engineering dream” that requires a significant shift in mindset from traditional relational modeling.
--------------------------------------------------------------------------------
2. Focal Modeling Mechanics
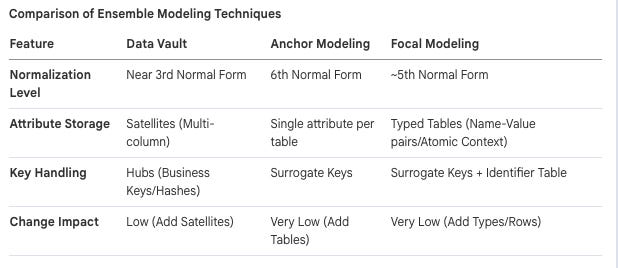
Focal is a form of ensemble modeling, similar to Data Vault and Anchor Modeling, but with distinct differences in how it handles attributes and normalization.
The Three Pillars of Focal
The model is built on three specific structures to ensure agility and minimize the impact of change:
Key Structure: Manages and controls the unique identifier.
Description Table: Holds the descriptions of data using “typed tables.”
Relationship Structure: Manages associations between keys without the use of traditional foreign keys.
Atomic Context and Named-Value Pairs
Focal utilizes an abstract method for storing attributes:
Typed Tables: Rather than standard business columns, tables use generic columns (e.g.,
start_timestamp,end_timestamp,value_string,unit_of_measure).Atomic Context: Data is grouped to answer one “atomic question” per row. For example, a monetary value and its currency are stored on the same row because one cannot be understood without the other.
Human-Centric Querying: The model strives to ensure that all data necessary to answer a basic human question is available on a single physical row, effectively reaching a state similar to fifth normal form.
Comparison of Ensemble Modeling Techniques
--------------------------------------------------------------------------------
3. Identity Resolution and Key Integration
Identity resolution in Focal addresses the challenge of recognizing the same entity across disparate systems where identifiers may overlap or change.
Identity vs. Identifier
The framework makes a critical distinction between two concepts:
Identity: A stable, immutable surrogate key that represents a unique instance of data throughout its entire lifecycle in the analytical system.
Identifier: A business-derived value (e.g., account number, email) used to find an identity. Identifiers are unique within their own data space but may change over time.
The Identifier Table Pattern
Focal uses a technical “Identifier Table” to manage the relationship between multiple identifiers and a single identity.
Key Collision Avoidance: By using source-system prefixes or concatenated strings, the framework prevents different entities with the same business ID from merging.
Multi-Identifier Mapping: The table allows multiple identifiers (e.g., a Social Security Number and a Customer ID) to point to the same surrogate key.
Key Propagation: When a new system introduces a new identifier (e.g., a local ID) alongside a known one (e.g., SSN), the framework automatically propagates the existing identity key to the new identifier.
--------------------------------------------------------------------------------
4. Performance and Cloud Optimization
As data architecture has moved to cloud platforms like Snowflake and BigQuery, the Focal framework has evolved to manage costs associated with columnar storage and large-scale lookups.
Single vs. Multi-Identifier Modes
Cost Efficiency: Performing lookups for surrogate keys on billions of rows is expensive in the cloud. Focal now allows entities to start in “single identifier” mode (using natural or hash keys).
Automated Migration: If an entity eventually requires multiple identifiers, the framework uses metadata-driven scripts to automatically migrate the data from a single key to a surrogate key structure across all related tables and relationships.
Storage and Indexing
Relational Databases: Focal tables are “deep” rather than “wide,” making them highly efficient for indexing due to their consistent, repeatable patterns.
Columnar Databases: The framework’s reliance on unique values and patterns works well with the compression algorithms of modern cloud data warehouses.
--------------------------------------------------------------------------------
5. The Impact of Artificial Intelligence
The emergence of AI and LLMs is viewed as a turning point for metadata-driven frameworks like Focal.
Devaluation of Manual Coding: As AI becomes capable of generating code, the value of manual programming skills decreases. The primary value shifts to the ability to design and understand complex systems and architectures.
Machine-Readable Architecture: Because Focal is entirely pattern-based and metadata-driven with no exceptions, it is exceptionally easy for AI to interpret. An AI can read the metadata layer to understand the data layer and answer business questions without the “cheating” or “bespoke” code often found in manual implementations.
--------------------------------------------------------------------------------
6. Significant Insights and Quotes
“The value of data warehousing... was the understanding of data. The value was not in the code. The code had a secondary value in the architecture.”
“Your coding skills are not that valuable anymore. Your ability to design and understand systems, how a good design and a good architecture is, becomes much more important than being very skilled at programming.”
“The metadata is our pet; the code is cattle... we end up protecting or caring about that metadata... because the code becomes disposable.”
“Focal... can create an extremely non-destructive architecture that is very easy to change and add data... without affecting anything else in your architecture.”
Tired of vague data requests and endless requirement meetings? The Information Product Canvas helps you get clarity in 30 minutes or less?
Transcript
[00:00:00] Shane: Welcome to the Agile Data Podcast. I’m Shane Gibson.
[00:00:04] Patrik: This is Patrik Lager.
[00:00:06] Shane: Hey, Patrick. Thank you for coming on the show. Looking forward to this one today. Today we’re gonna be talking about focal data modeling and identity resolution. But before we rip into that, why don’t you give the audience a bit of background about yourself.
[00:00:19] Patrik: Yeah, I’ve been within the data area for the last 25 years working with data warehousing mostly, but more or less just integration is a lot of work. I worked in SOA projects and other kinds of integration areas as well. I’ve been around and seen a lot of things on the way. I also have been one of the main developer of something that is called the focal framework and the Focal modeling Method. So I’ve been working with that since 2004. Or less. The focal came along 1998 by a man who invented it more or less, but then he and I, plus a lot of other people, worked [00:01:00] a lot with developing it and moving it forward, so to speak. So that’s me.
[00:01:04] Shane: focals been around for a long time, but it’s not well known. In some European countries is relatively well known, but in the rest of the world it’s not. Why do you think that is?
[00:01:16] Patrik: The focal framework has a Achilles heel, if you want to call it. It’s an extremely abstract way of using data, but what it makes, happens, it’s, it can create an extremely non-destructive architecture that is very easy to change and add data and change data without affecting anything else in your architecture. Which makes it very agile and very efficient when building things. But as I said it’s an engineering dream, so to speak, has been a lot of smart people working with it. So it’s not easy to take in to learn. And that has been, its Achilles heel, so to speak.
[00:01:57] Shane: And when you talk about focal being a [00:02:00] framework, can you just describe what you mean by that? Because a lot of times we see data modeling patterns that are described as frameworks or methodologies and really what they are as a good way of structuring data and not really much around it. Or sometimes we see methodologies that are agnostic around the data modeling patterns that you can use.
[00:02:19] Whereas from what I understand, focal kind of binds those two things together closely. The framework and the modeling patterns are coexistent is that right?
[00:02:28] Patrik: Yeah. The, the focal framework as it all started with the focal modeling technique, but then it, it became a focal framework was more for documenting. Really what we ran into in all of these projects we work was the documentation always got outta line from what we implemented.
[00:02:47] It doesn’t connect it after a while. So the idea was that we would capture all the metadata models mappings rules and stuff like that into a framework that then would generate the [00:03:00] code for us and generate the things and hold lineage and everything in it. So that became the framework, so to speak.
[00:03:07] You could call it a automation engine, but it’s much larger because it also works as a. A vocabulary and description models holds all kinds of lineage, business lineage technical lineage, operational lineage. It’s all over the place, so to speak. The metadata model is pretty huge, is like 80 tables containing all kinds of metadata around what you’re doing.
[00:03:30] So that’s the framework, so to speak.
[00:03:33] Shane: so if I play that back it’s a technical framework on how you can implement and automate the focal patterns. So it doesn’t take care of people and process, it doesn’t to talk about standups or the way teams are structured. So it’s more in that how you build a technical framework to implement and execute focal without having to handcraft code on a regular basis to make it work.
[00:03:55] Is that right?
[00:03:56] Patrik: Yeah, exactly. The thing was that we, at one point [00:04:00] we came to the conclusion that. The value of data warehousing or the value is the understanding of data. The value was not in the code. The code had was a secondary value in the architecture. So we wanted to make the focus on understanding what you’re doing, understanding data, understanding the business, so that was the focus, and then could use that knowledge to generate the code instead of writing it, and then also always be in sync.
[00:04:29] The documentation would always be in sync with the code because the documentation creates the code.
[00:04:35] Shane: And there’s been a few of us that have been working on this idea of metadata driven data tooling or, active metadata or config driven. Now the new buzzword is context driven. I always saw three patterns in the world. There were the, let me just write a blob code. The blob code executes, it’s it’s on its own.
[00:04:57] It has no relationship with anything else. It’s pretty much gonna do with the [00:05:00] heavy dating work from the left hand side, the raw data history all the way through to consume. And then the next one is tooling that allows you to write blobs a code, but then produces the documentation after the fact.
[00:05:13] WhereScape was probably old enough to remember that that was one where, a lot of the value was when you generated your code, it created the documentation for you. And if I look at people using DBT, a lot of it was around that documentation, that lineage that you got outta it.
[00:05:26] And then there’s a smaller group like us where we said, create the documentation first. And then let the documentation effectively generate the code, So we define the metadata, the context, and then that code will get hydrated based on that core. And we end up protecting or caring about that metadata that config because the code becomes disposable.
[00:05:48] The metadata is our pet the code is cattle and DevOps language. And we see tooling come outta that metadata driven Pattern over the last 30 years, [00:06:00] but it never really gets traction. Why do you think that is? Why do, and we still keep doing it because we know it’s much faster for us.
[00:06:06] But why do you think that this middle ground where people can write code and then document it after the fact always seems to be more popular than defining the metadata, the logic, and letting it hydrate the code for us.
[00:06:19] Patrik: The love of the code. That’s the thing. everyone who is a developer loves their code. They are proud of it. They want to do it. They want to show how good they are at it. And then they come a tooling, a framework that you do not need to be good at writing code. You need to be good to understanding the business and describe the business and describe models and create things like that. And it’s hard to get organizations to accept that because you get often a a lot of fight back from the development side that says you can’t write as good code as me. And I’m better at that. And then always it comes. One of the biggest thing is often that they say, but can you do this? And [00:07:00] you say, no, you can’t do that. Okay, then it’s useless. Even if you can do 90% of the organization because you can’t do the 10%, it’s useless. So they. Drive that line up in again to their own management side. And then it’s, it becomes hard to go, to come into companies doing that. They probably feel threatened as well.
[00:07:20] The interesting point is now with ai, there’s no way out anymore. This is what’s gonna happen. Your coding skills are not that valuable anymore. Your ability to design and understand systems, how a good design and a good architecture is becomes much more important than being very skilled at programming.
[00:07:42] Yeah.
[00:07:42] Shane: Also writing code by hand takes time.
[00:07:45] It’s busy work. So you can be busy writing that code and you’re not having to engage with the stakeholder side to understand the value, deliver that value incrementally. It, it’s not unusual for a data team to be able to do busy [00:08:00] work for a month and actually deliver nothing to a stakeholder.
[00:08:03] We, we somehow have this expectation, and I’m with you, I think the LMS and Gen AI are gonna reduce their expectation timeframe that a month, doing busy work is is not gonna happen. Vibe code and LLM or use a metadata config driven framework pick your choice. But I’d rather leverage an architecture that somebody else has created for me that I know works than let the LLM guess at an architecture that hasn’t been proven before.
[00:08:29] Okay. So framework is the technical implementation of fo. Focal started out in 1998, I think you said, as a data modeling paradigm. Do you wanna talk me through the focal modeling just for people that are more familiar with other modeling techniques and how it’s the same and how it’s different?
[00:08:46] Patrik: Yeah, the focal has been from the first point really method data driven. But it came up with the thought of three parts within the model where you controlled the key and that was its own structure. [00:09:00] And then you had a table that represented the description of data, and then you have their own structures for relationships.
[00:09:09] So you never had foreign keys between tables. And this was not my idea, this was the one who invented it. That this is how it should work. Because he had seen that complexity growth and that changes always happened. And when changes affects the model and when it affects the code, it becomes much slower to change.
[00:09:32] And a data warehouse after five or 10 years becomes very complex. So he was trying to find a way to do, to lessen that effect. And the thing is, one of the things that is making it abstract from a point of view is that the tables that are holding the descriptions are what we call typed tables. You don’t have normal business attributes, columns in the tables. They have generic columns like [00:10:00] start timestamp, end timestamp value string, the numeric string unit to measure. And then you have a key or a identifier of the information that lies on the row. So it’s what we call an tight key or an atomic context key.
[00:10:18] But what really says is it’s like a name value pair, if you know what that is. But it’s the inventor, he said it’s modeled name, value, pair, because it’s not one value and one key. It is one key. And you can have up to five different attributes if those attributes belongs together. So this is one of the, one of the problems with Focal, everyone you talk about it is it has a lot of underlying philosophical ideas and theories that doesn’t match how we do normal data models. So it’s always an abstract step to take in your mind, but why do you do that and how does it work? But from a, from, if [00:11:00] you want to simplify it very much, you would say that the tables that hold the description are named value pairs. You could say. So you have a ID or a key or what you normally that name and that says what is in the value string. And then you can add new attributes. They are just new names and they hold their own values. So you never change the table, you just add new types of data into that. So that is one of the biggest differences with normal data modeling really. So it’s it’s built for agility. More or less change, do non-destructive change.
[00:11:37] You can add attributes, remove attributes, and you never change the code. You don’t change the tables, you just do the change, so to speak.
[00:11:45] Shane: So let me play that one back. So you talked about first object is a key. Second object is a table which describes the values effectively and the key, and there’s some unique technical architecture around that, or modeling architecture compared to most [00:12:00] patterns. And then the third object is relationships,
[00:12:02] the keys that have a relationship at a point in time. my understanding is that is a form of ensemble modeling, You are decomposing the key from the descriptors of the key and you are decomposing the relationships and holding those separately. So that’s true, right? Focal is a form of ensemble modeling.
[00:12:20] Patrik: Yes that it is.
[00:12:22] Shane: Excellent. And then there’s two other ones that I know of, There’s data vault as one form and anchor modeling as another. So what I might do is just actually we’ve never had anybody on to talk about anchor. I need to do that but let me try and just play back what you told me around focal and how I think it’s different to data vault and anchor modeling.
[00:12:40] And I’ll get the anchor one wrong ‘cause like I said, I haven’t had anybody on to explain it properly. So the first thing is both anchor and data vault hold the key in a separate object like focal does. So that’s the same, correct.
[00:12:53] Patrik: Yes,
[00:12:53] Shane: Okay. And then in data vault we’ll hold one or many satellites that hold the descriptors or the [00:13:00] attributes against those keys.
[00:13:02] But we will hold a table that has, or a view that has many columns. So if I have person’s name and person’s age or date of birth, I will hold those as columns in the satellite and anchor. My understanding is I would hold each of those attributes as a separate table.
[00:13:20] Patrik: yes, that’s
[00:13:22] Shane: And what you are saying is, in focal, what we do is we use a named peer key.
[00:13:26] So we’re making those columns rows. However, there’s an extra little bit of complexity or value in there that you can hold multiple values against one pair. So I could decide to have name and date of birth. And what sounds like a Jason string is it’s a way of. Typing an object and having a subset of values against it.
[00:13:50] Is that right?
[00:13:51] Patrik: No the underlying theory, you can do that, but that’s not why it was designed for it. It is designed for what we call an atomic context. And the atomic [00:14:00] context is, so the key but we hold is we call it the atomic context. Key is a group of attributes, one, two, many, but five more or less is what we have in the tables, and it is supposed to answer one atomic question. So if you put a shoe number and first name, you don’t have an atomic question for that, right? Because you want to ask what’s your first name? What’s your shoe number? That’s two different questions. So they would be two different atomic context. But on the other hand, if I would say, what is the loan amount I have on my loan that I, my sign, my original loan amount, I might say it is 1000 euro.
[00:14:43] Because you can’t answer the question of a monetary value without its currency. So you need to have the value and the currency on the same row. Therefore, we have, as an example, we have a unit measure that we call unit to measure column that you say then, so you use the [00:15:00] Val Nu column and you say That’s 1000.
[00:15:03] And then in the unit measure it says Euro. So then you answer the atomic question. And as another example, more complex one is like a balance. That you have a balance. And to understand the balance, which is a point in time data, is only true at a certain point in time. You need the balance date. When was this balance value true? And what was the unit to measure of the balance? So obviously sudden you have three attributes within the same atomic context to be able to answer the atomic query. so this is more like from a human perspective think how does human answer ask questions? you can ask who are you?
[00:15:39] And you will get a lot of things. But if you ask an atomic question, the idea is that all the data should be on the same row. To answer that in the physical table.
[00:15:48] Shane: So let’s go back to that example then. So if I’m holding balance on my bank account, then I need to know what the point in time, the date time of that balance is. And I probably also [00:16:00] need to know what currency it is. So what you are saying is you hold those attributes together because actually they need to be together to answer that business question or to provide the context of one of those numbers.
[00:16:13] And therefore, rather than holding it outside of the physical structure in some form of, physical data model where I know I’ve gotta go join that with that, or query that row and grab these three columns. You’re actually saying by bounding them together in a row, the answer’s already there, You have to grab them all because we went to the effort of putting them there because that’s the information that you need to actually answer a question around what is my balance.
[00:16:40] Patrik: Yeah, so you can almost see it like a normalization of data. Because if you would have a, if you had a satellite in data vault, you could have , these three columns that we talked about, the date the value, and the currency. And then you could have what kind of classification balance is this?
[00:16:56] What is, so you just added up. But as we do [00:17:00] that, we break it out. So these, this answer one question, and these columns also these questions and break it out in rows then and these on, in, in in anchor. They go all the way. They do not care about how data from a human perspective is represented.
[00:17:17] They just break it out totally mechanically. One attribute is one table. So you have the value in one table and the currency, another table, and the date in another table. And then they generate views that joins everything together. so it’s three different approaches. Sometimes when I talk to last Runback, who is the inventor of Anchor, we talk about it, he says, anchor is in six normal form. And he, and not from a truly formalized perspective, but he says it feels like focal is fifth normal form somewhere around there. And then we have data was very small, third normal form.
[00:17:53] So it’s, you could see it like that. It’s more normalization is.
[00:17:57] Shane: And it would be interesting when you start putting [00:18:00] LLMs across it, because with data vault we’re gonna have to provide the context of which columns, which attributes in the satellite actually have value given the business question and anchor, we’re gonna have to say which tables right? Effectively need to be put together to answer that question.
[00:18:16] So that context is held outside the data. But in focal, what I think I’m hearing is actually the data has context as well. So if I give it, that name peer key and it can see that there is a balance, a currency and a date time. It’s gonna be pretty good at saying those three things are important to ask the business question of what was my balance, in New Zealand dollars.
[00:18:38] Okay. I can see doing it. One of the things that people often say against any of the ensemble modelings is, oh, storage is too expensive, it’s too hard. And so I can see that the estate currency, we’re gonna store currency again and again, right Where it’s bound to the context of one of the other attributes.
[00:18:57] In my view, storage is cheap now. And [00:19:00] actually with coer databases actually querying across tables as more expensive than querying within a table. But what have you found that’s one of the pushbacks with focal is data storage and duplication is bad. ‘cause it was 30 years ago when we had mainframes.
[00:19:15] Patrik: No never run into the issue of of storage. Really. And more, when we move really far back in the early 2000 when we had the normal relational databases the easy thing with the focal was that it was so easy to do, set up good indexes because the tables looks exactly the same all the time.
[00:19:34] And the, you could say the, the logic for True Delta always looks the same and always how you query it looks the same. It’s always the same. So, it was very easy to set up good indexes. So you even then the tables became very deep. It still worked very well because the indexes was so well defined and the Pattern was reusable all the time.
[00:19:57] So it just worked, so to [00:20:00] speak. What I’ve seen on the other side is that when we moved up into the cloud area where indexes is not so important anymore or important, but they aren’t, doesn’t exist, so to speak, true indexes but they are column narrative, right? Often snowflake and if you look at BigQuery, so on and so forth it’s really efficient because it doesn’t need to store everything, right?
[00:20:24] It’s just store one unique value. It is a really good what do you call it when you press data together? yeah. so focal works very well with those formulas for doing that. So it becomes very small in storage instead because it doesn’t need to store each and every value in the engine, so to speak.
[00:20:46] Shane: And then from what you’ve said the focal framework and the modeling Pattern has basically described the types that sit in those name peer keys. So there’s a dictionary or a shopping list of types [00:21:00] that, that you need because they’ve been proven over the last, what is it, 20, 30 years.
[00:21:05] So you’ve probably gone through and figured out all the types that are needed, pretty much in, in most examples. And you get those kind of free when you are using the methodology or the patterns.
[00:21:14] Patrik: Yeah. You always have to keep in mind that the focal today is the data layer, so to speak, where the data is size is very crucial. See, machine driven is not for the human eye. It’s been very specialized to be fully met data oriented. So there you can’t really look at look at the table in, in the focal data model and understand what kind of data is there, you need to add them.
[00:21:41] Then metadata layer or knowledge layer upon it, that is directly related then. But but everything describes what is there, how it is stored, and everything is up in that layer. So that layer is the, the heart of the solution, so to speak. The physical layer is more just [00:22:00] how do we make this reusable?
[00:22:01] How do we not care about what the human think, care about good engineering sort of principles? And that has been very effective. And now when AI comes along, it’s all of a sudden it’s shit. the machine understands it without a problem, but a human thought was hard for a machine.
[00:22:18] It seems like the AI goes like just, okay that’s not hard.
[00:22:22] Shane: Because it’s patent based, right?
[00:22:24] Patrik: Data, everything is described. So he just reads the metadata layer and then he understands what’s in the data layer. And then you can just ask him questions
[00:22:33] Shane: and there’s no exceptions
[00:22:34] because it’s meta data driven. . There’s no, oh Bob came and did that one and he cheated and Yeah. That’s an exception that you’ve gotta deal with. .
[00:22:41] Patrik: No. So that’s, yeah, it’s fully patterned. So it’s, it is, as you say, there is no exceptions that it has to take into consideration
[00:22:48] Shane: So one of the negatives that you often hear around modeling patterns like data vault is consuming, the data is hard.
[00:22:56] There’s a lot more tables, a lot more joins, even though it’s pattern [00:23:00] based, people that try and query it directly have a little bit more work. And what we always say is your consume layer should be automatically generated,
[00:23:07] it’s a pattern based design pattern. So creating the consumption patterns can be automated and you can use one big table with. Dimensional modeling or whatever, anything that flavor that you prefer to query the data. But those patterns for querying, it should be automated.
[00:23:23] I’m gonna assume that for focal, it’s the same that you wouldn’t expect a human with Tableau to go into the core focal data model and try and figure out how to query it.
[00:23:32] Patrik: No, it’s certainly not. No. It’s the focal framework itself creates, automatically creates views more or less like anchor does. So it you as a human never reads the physical tables. You go through the views, which will pivot the data into this is the customer view.
[00:23:50] This is a customer table. It looks like a normal table. When you look at it with all the column names and stuff like that underneath, it’s a totally different thing. But for a human, you as [00:24:00] go in and. Access the views and it looks like a normal table. So that’s how we have abstracted the complexity.
[00:24:07] So you don’t work against the physical the machine does that. You just read the views and you don’t have to care how complex or how strange or abstract it’s underneath really. So that’s more or less how we work with it. You don’t go in and hand code a dimension from the physical tables?
[00:24:25] No.
[00:24:25] Shane: And that’s part of the framework. When you talk about your metadata repository, having 80 tables, that’s where you’re gonna define these keys. These name peer keys, the relationships, and then it’s gonna generate the physical structure under the covers using the focal modeling technique. And then it’s gonna also generate the views that you need to make that data useful
[00:24:47] and usable when you query it.
[00:24:49] Yeah.
[00:24:49] Patrik: Yeah.
[00:24:50] Shane: And that’s the value of the framework over and above the modeling pattern, correct.
[00:24:55] Patrik: Yeah. I think I, I agree that most of them, both from anchor and data [00:25:00] vault and focal and ensemble models, it is harder to write queries against it. You can’t really dodge that’s how it is, but there is a reason for it, and that’s what people forget. So you can’t say it’s just as easy as a dimensional model.
[00:25:16] No, it isn’t. But there is a reason why the ensemble models looks and works like they do, which from an architectural perspective and longevity of the system and changeability and stuff like that. these layering ideas or have layers, is that you have a layer which is specialized on a. Specific area and use the modeling technique that support what you need to do in that layer. Have another layer that makes it easier to do other things, but don’t suboptimize the layer by trying to do everything in one layer. you have to have sort of a system design mind to understand when and where to use things.
[00:25:56] Shane: Yeah, that idea of a layered data architecture and use the modeling techniques [00:26:00] that have the most value for the problem you’re trying to solve. And then automate them and standardize them so they’re part of your architecture. Not little things bolted on the end that, people forget that for this one we somehow use something that was slightly different.
[00:26:13] Last question around that though. The focal framework itself, it’s open source, correct.
[00:26:17] Patrik: at this point there is a focal CLI that we are about to release it. It’s a lot of testings that goes round. The focal framework itself is not in GitHub at this point because more or less, it’s just so hard to understand it. So we need to abstract it, give you tools to use it, so to speak, so you don’t have to be a focal expert to use it, because that just takes too much time, more or less
[00:26:45] Shane: So the other thing we were gonna talk about is how Focal helps us with identity resolution. So this idea that, you know, one of the largest problems always is we see the same person in multiple different places and [00:27:00] systems and we want to stitch them together or the same organization.
[00:27:03] And that is a big problem that most people ignore, right? They focus on the simple problems when they bring out new patterns, frameworks, methodologies. They do the nice, customer orders, product simple ones. So let’s deep dive into a identity resolution and how Focal helps us with that.
[00:27:21] Patrik: Okay. Let’s let me set some concepts first around it, on why we’re doing it just for the audience. So when I’m talking about entity resolution or key integrations, I also used to call it is that we have two things. Two concepts, and that’s one that you have something is called an identity, and that is something that is stable, immutable key that represents an instance of data. And that key should be it doesn’t have to be, but it should be unique throughout the whole analytical system. And it’s [00:28:00] identifies a thing on event unique over its whole life cycle. So it’s immutable. So that’s an identity when I call it identity. The other one is to call an identifier, which is a way of identifying a thing in event it has to be unique within its data space. Might not identify the instance as its full lifecycle, but we should strive to find one. So these are two different concepts. The identity often is called surrogate keys is normally represented as a surrogate key in your system. And the identifier is what people sometimes call business identifier or something like that. But it’s good to understand that you should keep those two apart. That there are two different things and that they are there for, to handling things differently. The other thing is what are we trying to do and what do we not want to happen when we do the sort of integration?
[00:28:53] Key integration is that one thing we don’t want to happen is key collision. The idea is that we have two [00:29:00] different systems both holds accounts and they have an account number series on them and we send them into our account focal or hub or whatever. And we use the account number as the identification because it’s the business identifier, but for some reason these numbers are overlapping.
[00:29:17] So we can start getting key collision. That means that. Two different accounts that are two different instances in the real world, start writing their data on each other and changing data back and forth because they are not truly the same account. That’s a key condition area that we want to avoid. The other thing is that we want to achieve key integration. And and that is the thing that we want to, if they are the same thing in two different system, we want them to integrate on the identifier or the key, so to speak. And the, this is the hard part when working with this is to understand. [00:30:00] How unique should I do something and make something and still make it integrate? So let’s say you could have this account thing and you go okay, but I set source system ID in front of it, and then the account numbers will be unique. Yeah. And then you have two different customer systems and the same customer lives in both system, but you just go, wow.
[00:30:21] But we set the same system ID in front of the customer ID, and then it’s unique, but then we all of a sudden don’t get the key integration that we want to happen because we have made it too unique for how it works in the it. So this work, as you said, this work with integration and entity resolution is. It’s really hard work. It’s not something that just comes along freely is you have to put time and effort to understand the IT landscape, the business processes. How does data move? Where is the unique instances of things and where do they live and how do they move in the IT landscape [00:31:00] to be able to understand how should I build my identifier, because this is what we talk about, so we need to create an identifier. Some people talk about business identifiers. for me, that doesn’t ring correctly because I talk about I normally want to say integration identifier because for me, business identifier is something that the business can use to identify things, but it doesn’t have to be unique for their work, in their daily work.
[00:31:28] So you could have something that is true in one point in time, that it’s unique, but it can change. And it’s still, the business uses it because it works from an operational perspective. But from a analytical system where we historize things and keep track over time how things changes, we need identifiers that stay true throughout the life cycle as much as possible. So there is always that kind of work we need to do to understand how [00:32:00] do we create the identifiers so they will truly integrate and not end up with a key coalition. So it’s hard work, more or less
[00:32:10] Shane: There’s, there was a lot in there. So let me unpack it and try and map it to some patterns that I understand, and I’m probably gonna get them wrong. So I’ll pause after each one to make sure that I’ve got it. So the idea of key collision, so let’s use let’s use accounts that, in system one, we have an account, which the account sequencing numbering is 1, 2, 3, 4,
[00:32:32] so it’s a number. And then in system two, we have a separate series where it’s A, B, C, and based on that, if both of those are held true forever, we know there is no key collision, we can trust that as a unique. Account record, and we’d never collide. But if system one is 1, 2, 3, 4, and system two is 1, 2, 3, 4, and they’re not integrated anywhere else we know that potentially we’ll see that 1, 2, 3, 4 come through from each system, but for a different [00:33:00] account, account for Bob versus account for Shane or, account for savings versus an account for investment.
[00:33:07] And so our natural way of dealing with that is to put source identifiers at the front. Yeah. So system 1, 1, 2, 3, 4, system 2, 1, 2, 3, 4, and now we know we will never get a collision. So that’s the first Pattern that we typically do is that correct?
[00:33:22] Patrik: Yes.
[00:33:22] Shane: And that source and account combination, is that what you call an identifier?
[00:33:30] Patrik: Yeah, it could be, but it could be multiple. You could use multiple columns to create an identifier. So it’s depending on your physical realization of how you want to do it, you could keep the columns apart, but in the focal we, at least we concatenate all the different columns we need to create a unique string of data.
[00:33:48] Shane: Yeah, but that’s the identifier because we can identify that was true at that time. It’s a fact. We can see the data there. We didn’t make it up. We didn’t infer it. It’s a fact. Okay. And then we [00:34:00] know that if we want to say, this account system one is the same as this account system two.
[00:34:06] And now we don’t have an identifier that is exactly the same identifier. We have to infer that they are the same. And it’s like a surrogate key in my head. We’re trying to find this unique identity. I’m just trying to get my language right, the unique identity to say that actually is the one thing that looks differently elsewhere and it’s the same.
[00:34:26] Is that right? So we’re creating this unique identity ID that then everything’s bound to if we can match it. Is that right?
[00:34:34] Patrik: Yeah, I mean it’s the same for data vault people that you have the business key and then you have the Sid, right? It’s the same principle. You have an identification identifier, which is related to a surrogate key. So that’s just to keep them apart, so to speak. That’s what they have two different sort of workings in the system.
[00:34:54] Shane: And so obviously creating that identity ID, because that becomes this golden [00:35:00] id, It’s this immutable thing that we bind everything to when we find something that’s related in the future. And we can see changes over time, so if my account number goes from 1, 2, 3, 4 to 5, 6, 7, 8, 9 a year later and we bind that back to the identity Id, you still know it was my account.
[00:35:18] it’s identifier changed and sometimes happens, especially when we’re using email, When we use email addresses the identifier or name, we know that those identifier IDs will change over time and they cause us a major problem. So what we’re trying to do is find that, that golden identity ID for the thing the event, the person, people place or those kind of concepts who does what’s all those kind of concepts that we wanna manage.
[00:35:42] Is that right?
[00:35:43] Patrik: Yeah. Yeah.
[00:35:44] Shane: Okay. Lots of people talk about that and then they leave it to you to figure out how to do it. So take me through the next bit.
[00:35:52] Patrik: Yeah. So since we are talking about patterns let’s talk about how, first, how data vault does it and Anchor does it just to [00:36:00] make it see, and then we go down to how focal does it. So in the data vault, we already touched on it, right? You, we have the hub, and in the hub we have a business key and we have a c and a surrogate key.
[00:36:11] Now I know a lot of people have discontinued use of surrogate keys in, in the data vault area because they’re using hash keys. And there is a reason for that, and I agree that data vault should do that because they do not have the ability to relate multiple identifiers to one identity because it’s hardwired in the hub. So if it is a one-to-one relationship between the one identifier and it’s key. There is no really architectural functionality for the surrogate key. You can just as well just hash the identifier and then you have a key that always works through. Instead, when the reality hits us in the face, we all of a sudden understand that, oh, this one can be identified multiple different ways. So you could have [00:37:00] a customer ID and you have a social security number, and both are used to be identifying you in different systems and in data vault. if you use the customer ID and it has its surity or you just hash it, that becomes one instance of the customer. You do the social security number, it becomes another instance of the customer. Or then they use a same as link that says This ID is the same as this. ID from an instance perspective. So that’s how they Do it in their solution. In anchor, they point at an attribute table. So you have, in the anchor, you only have the surrogate key, and then they point at the table and one of the attribute tables, and you say, this one is also used as an identifier.
[00:37:44] So their code uses that for lookups. Okay, I, I have my identifier, I check there and then I can pick up from the anchor, I can pick up the surrogate key, I get the surrogate key, and then you have the pickup and they have the ability that they can choose, okay we want [00:38:00] another attribute as well as part we could be able to identify with social security number as well.
[00:38:06] And then they can point in the table that also social security number. The issue is that they have to generate the code or change the code because it has no generic solution around it. So it’s. The code is changing. It’s is a destructive change in the architecture. When you need to add a new way of identifying things, then you get a destructive change in your code.
[00:38:28] So you need to change your code. In Foco, we have what we call an idea for a table, which is to identify a table, which sole purpose is to integrate, to be used, to create integration and hold the relationship between the identifier and the key that are created. And how this works is no magic in the focal framework.
[00:38:53] As of today, there is no fuzzy logic solution or things like that. It’s only [00:39:00] purpose and only functionality is that you can, connect multiple identifiers to one key if you have them in the same table. More or less. So let’s say you have a table where you have your customer ID in the table, and you also have the social security number in the table, probably from the source, right? You can then point out and say, the customer Id identifies the customer, and the social security number identifies the customer. How do we know it’s true? They are on the same row in the table, right? So we know by how the built that they belong together. There’s no magic really.
[00:39:36] It’s just we can just point out multiple things and those different columns that we use to identify becomes their own identifier stream. Now, in the identifier table, there is, I’m not gonna talk about the whole, because there’s a lot of technical things in it as well, but from a conceptual point of view. You have one column that is [00:40:00] called identifier, and you have one column that is called key. And the thing is that each row represents the relationship between an identifier and a key. Now in the code, if you point out social security number and you point out the customer ID as identifying the identifier code will then put both of those into the same SQL, and then he will check for each of those. He will do multiple lookups, one for each. We will look up with the string for the customer ready, we’ll check against the identifier table. Do I have a key for this, yes or no? Okay. And then he checks for the social secured number. Do I have a key or not? In my identifier table, if there is no key, new key is created. Both of these becomes pivotal to its own roles. So the social security number becomes related to customer [00:41:00] key one. the identity, the customer id, key one, and the social security number will also be aligned to the customer key one, so to speak, this surrogate key. So now they are aligned. The, one of the interesting point is, let’s say we also have something else I don’t come up with a good example, but some kind of other identification of a customer, maybe in the same table, but could also be in another table. So in another table, in another system, we have the, let’s say the social security number, and they have a local identification of the customer as well in another color.
[00:41:36] And they want, they need that because they have other systems that. Works with that identifier in the ILE landscape and not the social security number. so the thing is that when they map that system and say it’s a social security number and this local ID that identifies a customer from this source, when that goes in and checks the data in the identifier, he will check the [00:42:00] social security number and he will pick up a key number one, right? And then he will go with a local and he will find no key. But since he already found the key, he will propagate that key to the local ID and that will become a new row in the identifier table. The row that represents the social security numbers, relationship to the key is not multiplied, it’s just exists only one instance independently.
[00:42:26] How many system that uses it. So it just becomes one instance, one row per. Unique string, so to speak. So all of a sudden then you have three different identifiers related to the same key. Now the fascinating thing about this is that since the table is just identifier and key, and when you instantiate this Pattern, you do it for the concept.
[00:42:51] So you have customer identifier and then the table will call it customer identifier. And in the column there will be a customer, [00:43:00] IDFR column and customer key. And do you do it for product? Same thing. Product, ident. so from a patent base there is identifier, key idea, four key, that’s it. And then you just add what kind of entity you want to use this identification for. And the code is exactly the same for independently or which entity. You can also say independently of what industry you do it for, it doesn’t change. It is the same. So the table and the code works the same way independently or who you want to do identification on. So this Pattern is for me, it’s not really a focal Pattern. It is part of the focal solution. But from my point of view, you can use this for any modeling technique really. If you want to be able to create a surrogate key, you just create this look up table, so to speak. And you can have it for dimension modeling. You can have it for data vault if you dare to break the hub thinking. [00:44:00] And you can do it, you could really do it for anchor as well or yeah, whatever modeling method you want, as long as you, you like some sort of, I need to be able to have multiple ways of identifying things. But I don’t want duplicates in my data. I just want one surrogate key for it. It’s totally reusable for anyone to use.
[00:44:19] Really?
[00:44:20] Shane: So let me play it back to make sure I got it right and then we’ll jump into a couple questions. So what we’re doing is we’re holding a table, let’s call it table. And in that table there is a golden unique identity, something we are generating that we, that never changes to say we, we have an instance of a thing, and then we are binding that to identifiers we see.
[00:44:41] So in your example, I might bind it to an email address and a social security number and a passport number and a driver’s license number because each one of those are identifiers of a person.
[00:44:53] So what we end up with is we end up, in that scenario, we would end up with the golden key that we’ve [00:45:00] generated four times four rows, and then each of the related identifiers, social security number, email address, license, passport number, and the benefit of focal is.
[00:45:11] The framework does that automatically for you, so if you go and say, that social security number is the same as related to that driver’s license number because you have a table that tells you that, then the focal framework is gonna go and do an upsert into that golden table.
[00:45:28] If it hasn’t seen it before or say we’ve seen it before, I know that relationship exists, we’re okay. Am I right so far?
[00:45:34] Patrik: Yes.
[00:45:35] Shane: And so the benefit of that is if I look at something like data vault where we have same as links. I’ve gotta code fire the code. I’ve gotta build my old framework to go, how do I do these relationships?
[00:45:46] And frankly, I’m not so sure, but probably the same. And then, so that’s the first part of the problem, how do we codify or patternise the identifications of these keys without having to manually do it? And then the second one is [00:46:00] how do we then use that in all our queries to be able to let me query any data with any of those identifiers that is valid at the point in time.
[00:46:09] And that’s the bit that you are saying in the focal framework. You still you haven’t patternised or solved that automatically yet that still requires some human to do that query side of using that data, or is that something you have solved?
[00:46:23] Patrik: It’s depending on what, because, ‘cause from a focal perspective we more or less never use the identifiers for anything else than creating the relationship to the key, so to speak, if there is multiple ways of doing it, multiple identifiers. So I will talk about that a little bit later. But so the identify table is a technical table. It’s not about using as a business representation of things. , You have your key, that is a unique instance or something if you want to search or do a query on the social security number. Then the social security number also is stored in the descriptive data [00:47:00] as its own. It’s its own representation. So you search there for a social security number, and we have said that there is a, there’s a separation of concern here. We should have, the identifiers should be able to live and develop however they will need to be to achieve integration. While the business identifiers should not be contaminated by that. So the business identifiers is held on their own in its free form, it’s clear. So if we do a concatenation in the identifier table, it’s not done in the, on the business identifier. Social security number. Social security number if we need to say. Sweden social secure number, and Russia social for some reason. Whatever the number the idea or the, in the scripted table, it’s just the social secure number clean, so to speak, as a business from a business perspective, which means you could get up duplicates when you search for that. You could get two rows, one Russian and one Swedish guy. [00:48:00] But yeah, that’s how it works. Then you just have to choose what, whatever you want to have it, what do you want to see? So that’s a separation of concern in the architecture the identifier table is a technical table should not be accessed by people, so to speak, because the key itself is really what hold binds it all together
[00:48:19] Shane: And then again, because it’s pattern based, you’d assume that LMS would understand the role that technical identifier table plays because it’ll see it being used the same way every time, and therefore it should use it more effectively than we’ve got bespoke tables or other things that are used in different ways.
[00:48:38] And then I think you said it doesn’t solve the whole fuzzy matching problem, but again, there’s patterns and code bases out there that allow you to do it. So all you’d be doing is injecting the fuzzy matching logic. To determine what rows you need to insert or check for in the identifier table.
[00:48:57] Right.
[00:48:57] Patrik: No, there is no, you can do it, [00:49:00] but the code as it is today is just you have it on the same row. They mean the same thing, two different columns. Yeah. So there is no magic. I usually say that there is no magic. It’s just.
[00:49:11] Shane: Okay. we talked about three object types. We talked about a thing that holds the keys, a table that holds the descriptions or the attributes as name, peer values, and then something that holds the relationships of the keys, this identifier table that holds this unique identifier and the system identifiers.
[00:49:29] Is that a different object type or is that reusing one of the, just to get, I got a funny feeling. I know where you’re gonna go with it, but Yeah, it, is it a different object type or is it just reusing one of those? A couple of those three.
[00:49:41] Patrik: No, it’s an, it is a different object
[00:49:43] type In the focal. We have the focal, there is a focal table that holds the surrogate key Exactly. As a anchor key anchored us. It’s only a surrogate. As I said, the identified table is a technical table to achieve integration on the [00:50:00] key, so to speak. So it’s its own type.
[00:50:02] But normally when I talk to Hans, we talk about, he says, yeah. The concept is the key, even if it’s two tables.
[00:50:10] Shane: so like we have with Data Vault where we have, HALs and SALs and these other things that we need to do from a technical point of view that break the, there’s only three simple type of tables you need. I’m assuming within focal, there are other instances of that where there are other technical tables or objects that we need for certain things, or is this the only one?
[00:50:31] Patrik: this is the only one
[00:50:33] I mean from a physical data modeling perspective, but then you have the whole metadata layer, but that’s another animal, so to speak.
[00:50:40] Shane: then we get to the problem of point in time reporting. And so if I changed my email address as one of my identifiers, at a certain point in time, it’s gonna solve that problem anyway because I’m now going to automatically get another row in that identifier table to say, against this golden [00:51:00] key, I’ve got another identifier.
[00:51:03] And then in my queries I’ll be able to use that to say, was it this or was it that? Okay. Yeah. I’m just trying to think around the whole, changing of of identifiers and then how that goes back.
[00:51:14] Patrik: I mean there is always that There is, yeah, there is no magic. So if you don’t have a stable identifier and you change your email address, you only have email addresses an identifier, and then you change the email address and you don’t have a column that says this was the old email address or something. It will create a new key because he doesn’t know about the previous email address. but if you have a social security number and an email address, the social security number will be stable and you change the email address. It’ll add the new email address to the same key.
[00:51:48] Shane: But if I had a table that held a change of email addresses an event, and so that table held previous email and new email,
[00:51:57] then it should pick it up against that golden key that [00:52:00] the email address had changed. And so there’s just another identifier against that key. Correct?
[00:52:04] Patrik: Yes. Then it would do that
[00:52:06] the identifier table doesn’t care which column you use. So it’s just a generic column of identifier. You just have a string of values. That one is one you check. There is of course the ability to going up to the metadata layer and see. What attributes in the source was used to concatenate this string. So it exists up there, but in the physical from a code perspective, it’s just, here’s a string. Does that string exist? When it checks, when it do a looks up, it doesn’t care if it’s what column you use to create that string.
[00:52:39] Shane: And again, it goes back to that idea that the metadata or the context is held outside of the physical data, so if you’re using an LLM you need to make sure that both are exposed because if you give a physical focal data model with its , physical data to an LLM, it’s gonna struggle to understand the context of how that works.
[00:52:57] Patrik: Yes. Very much yeah.
[00:52:59] Shane: Okay, that [00:53:00] makes sense.
[00:53:00] Patrik: I can just do another thing around this because when focal started and for the up to, yeah, 2014 or something like that, and 15, the, or even later. But anyway the identifier table was not optional. It was always, you always have a surrogate key. That was how it worked. But when we moved into the cloud area, we the cost of doing a lookup when you have a lot of rows costs every time. So if you have an entity that does not have multiple identifiers, why should you use a lookup? Why do then you can just as well hash the thing or use the natural key, right? So in the focal framework today the multi identifier functionality is the optional. You always start with a single identifier point of view. So you set up your entities and if you don’t have any , multiple identifier at this point, you just run it as like data vault [00:54:00] or something. It’s just natural or hash keys. But the thing is then that when you come to a point in your development that you all of a sudden know, okay, we need both social security number and email address to make this work. Then you can, in the focal framework, then just point at the entity and say, now this entity has multi identifier entity. And then that gives you the ability to map multiple identifiers to that as you do your mapping and say, this identifies and this identifies. And then the framework will also migrate your data for that entity. So it will. Propagate the new surrogate key that is generated. Why when you deploy, before you load it deploys and take all the wall data, integrate it to the surrogate key that you have created and populates all the tables that are involved. this is also when you think about it from a ensemble modeling perspective, is you have an entity and it has three relationships, right? And you point at that entity and says, this one is now [00:55:00] multi identifier. So it has to run on a surrogate key. It also has to migrate the data in all the relationships. And once again, since everything is metadata driven and pattern based, once we figured out the script on how to migrate from the normal key or natural key to surrogate key, it works for every entity. It was just a one go. You needed to figure out how do you do this? How do we move what? What kind of things do we need to do?
[00:55:27] And once that is done, it was repeatable. So it became repeatable. So you don’t have to think about it either. Oh, how should I migrate then? No, it’s just point that it say this is multi identifier now, and then it would migrate itself.
[00:55:40] Shane: And this is one of the value of these frameworks that are put on top of these modeling patterns is that they have been built out over so many years, decades, they’ve seen lots of edge cases, and the framework then gets updated with those edge cases and then. That code gets tested. That [00:56:00] pattern gets tested at time and time again by many people and many organizations and many industries.
[00:56:05] And it pretty much becomes bulletproof versus a senior engineer writing it for the first time or, go and find a blo of code from somebody, and then obviously you’ve got all the get repos, you go and harvest, and now the new one is your vibe code on the LLM.
[00:56:18] But none of that is proven versus you go to a framework that’s been tested over decades and you know that those, each cases where they’ve been dealt with have been proven. One of the questions I always have is, when do I ever trust an organization who tells me they don’t have a secondary identifier?
[00:56:35] And my answer is never, because they’ll tell you they’ve only got one. And then, three to six months later another one will turn up in the data and they’ll be like oh yeah, sorry, I forgot about that. And so for me, yeah, I probably would just go with multi identifier in the beginning and wear the cost of the surrogate lookup
[00:56:52] Patrik: at the same time, you don’t need to when you have the migration script, so you just, you run it as single until you need [00:57:00] multi. Just automatically migrates your data over to multi identifier,
[00:57:03] and then it’s just for that, and then it’s just for that
[00:57:06] entity also.
[00:57:07] Shane: if I’ve got billions of rows.
[00:57:09] Patrik: This is something we have seen when we worked in BigQuery and Snowflake. This is really important from a cost perspective, really. Because when it’s huge data sets, it costs a lot to do those lookups, even if they’re really efficient. So still costs data especially since there are no true indexes and stuff like that on these platforms. So you, even if you do a very good setup for. For the order of data and petitioning of data and what, can do in these areas. It still costs money. so that was the decision why we said, we know that a lot of entities will get multiple identify over time, but until they do not need it, we can run it on single identifier code, so to speak.
[00:57:56] Shane: Yeah. And it’s that idea of optimizing where it makes sense.
[00:57:59] You know, [00:58:00] 1, 1 1 of the things we do is, we will for smaller volumes of data, when we see an event, we will just do an upsert where we see larger volumes of data and we know some things are gonna happen. We might do a petitioning replace, but the system takes care of it,
[00:58:15] because it. You optimize it for, okay, if it looks like this, do that. Because we know over time that’s gonna save us money. And if it looks like that, do this and we can switch between if we need to. But it’s that baking in optimize at the right time at the right place. And don’t be afraid to change it later if you can change it safely.
[00:58:32] Yeah. Whereas in the past we would never touch anything like that. You say to somebody, oh, can you go into your dimensional data warehouse and just rekey all the surrogates for me? Yeah. That’s gonna be a dangerous change, right? Because yeah, it hasn’t been designed to allow you to do that.
[00:58:48] Patrik: Oh, exactly.
[00:58:50] That’s
[00:58:51] Shane: excellent. All. If people want to get hold of you, if they wanna understand more about focal, if they want to learn more about the modeling [00:59:00] patterns and the framework, where do they go?
[00:59:03] Patrik: I would say you can either go to LinkedIn to my profile, or you can go to Daana dev, which is the project where we’re working with with a focal framework creating CI around it so we can, you can easily test it.
[00:59:20] Shane: And give me an example of what you mean by building a CLI out for this. What are you looking to achieve?
[00:59:25] Patrik: But it’s more like. Doing an abstractional layer of of the focal framework since it is complex in its sort of design to make it easy for people to use. So the Daana CLI works with YAML files where you set up your models and your mappings and then that get processed into the framework and then the framework creates the code and stuff like that. So it’s more like just ease of use. So instead of trying to figure out how you’re gonna use the focal framework, there is already a command line interface where you can [01:00:00] do all the things you want to do with it, so to speak.
[01:00:04] Shane: The metadata tables and the physical tables, they’re technology agnostic, right? So you can run those on any of the data platforms or data technologies.
[01:00:14] Patrik: Yeah, and not, there’s always these small quirks in SQL that the different platforms uses. the interesting point is a focal framework have had Oracle sgl, L Server snowflake, BigQuery Postgres. But we are now in the middle of our sort of re visiting the architecture. So now we have pulled us down to Postgres and BigQuery. Where we start to build up all the different platforms again. But it’s still certain parts are platform specific. But since it is metadata driven, the it’s not that hard. Once you get it to work, it’s just shift.
[01:00:58] And now with ai, [01:01:00] LMS also, they can easily translate your patterns. So you can go now I want this to work in Snowflake and just show them all the patterns, and then they just transform it over. You have to test it, of course, because it’s lms, you don’t know what they’re gonna do. But it goes very quickly to, to move to a new platform at this point.
[01:01:21] Shane: But if somebody was starting out and they, wanted to reduce the uncertainty of things they need to learn, then you’re saying Postgres and BigQuery is probably the safest way to start out, to learn on it
[01:01:30] Patrik: now you can go in for the homepage, that’s Daana dev and sign up for be a better be tester and try it out. And then we have building up a community around it because people was to be able to contribute and stuff like that.
[01:01:47] So yeah, we see where it goes for me it’s really fun because all of a sudden the focal framework becomes accessible for people that, that doesn’t want to put the energy or effort trying to [01:02:00] understand underneath the hood. And that’s really fascinating, I would say. So it’s really fun.
[01:02:06] Shane: And even if we look at something like data Vault, which is probably a lot more well known across the world even then it’s still, you’ve gotta learn some stuff. So anything we can do to remove that complexity and make it for people to, simple for them to use the patterns.
[01:02:19] And that’s a good thing in my view, right? But it takes time and effort to make something that’s complex under the covers simple to use and execute and get that value of automation and. Optimization out of it.
[01:02:31] Patrik: Yeah. Yeah, exactly.
[01:02:33] Shane: Excellent. Alright, thank you for that. It’s been a great chat. I now know a lot more around focal than I did a while ago.
[01:02:39] So thank you for that and I hope everybody has a simply magical day.
[01:02:44] Patrik: Same. Have a nice day everyone.
«oo»
Stakeholder - “Thats not what I wanted!”
Data Team - “But thats what you asked for!”
Struggling to gather data requirements and constantly hearing the conversation above?

Want to learn how to capture data and information requirements in a repeatable way so stakeholders love them and data teams can build from them, by using the Information Product Canvas.
Have I got the book for you!
Start your journey to a new Agile Data Way of Working.